Bayesian hierarchical model for company credit risk
Bayesian hierarchical model for industry-specific delinquency estimates
We used Bayesian hierarchical logistic regression to create better industry-specific payment delinquency estimates for SME lending. The scoring system provides a quantitative assessment of the probability that a loan becomes “bad.” Examples of this state include loan default, company insolvency, or bankruptcy.
Background
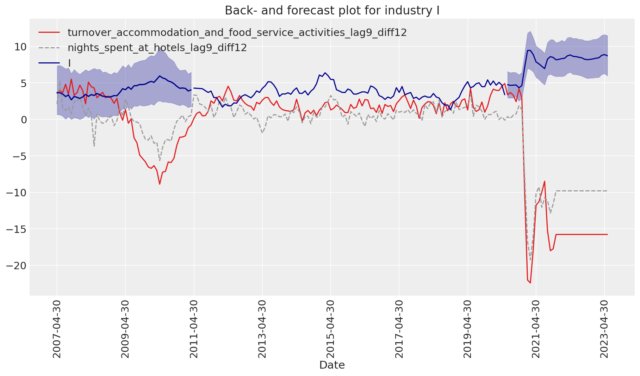
How much financial KPIs affect companies’ performance and their ability to repay loans differ depending on which industry a company operates within. A current ratio below 1.0 might be okay for a retail company since their cash conversion cycle is usually short. While manufacturing companies should have a current ratio that is significantly higher as cash conversion cycles are generally much longer.
The client is an American software company that provides solutions to financial institutions. Their offer includes technology for compliance, credit risk, and lending solutions used to manage risk.
The Solution
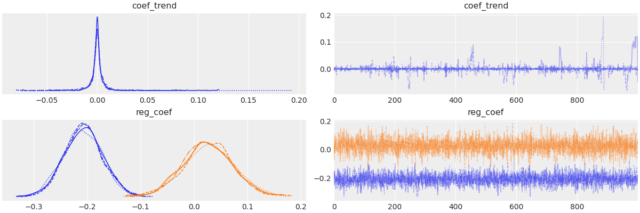
The common logistic regression would assume that all industries share the same regression coefficients, which, in Bayesian terminology, is called a pooled model. In the other extreme, we could assume a model in which each industry has its own regression coefficients— called an unpooled model. Both these alternatives are unacceptable given the aforementioned problem. As a solution, we used a partial pooling model, a so-called hierarchical or multilevel model from which we assumed different regression coefficients for each industry (as in the unpooled case) while the coefficients all share a similarity, drawn from a common prior.
How we did it
We developed the Bayesian model using the probabilistic programming library NumPyro. It has a JAX-based backend so it can be really fast when compiled, and it can run on GPUs. Slow sampling is otherwise a common problem when building Bayesian models.