- 10 min read
- Cross-industry
- Oct 2025
Misaligning LLMs with supervised finetuning

Introduction
Large language models (LLMs) have quickly become part of our daily lives. They are powerful tools that can significantly boost productivity across a wide range of tasks. But with this boost in capability, an important question arises: can LLMs also be used in unethical or even illegal ways?
Since they are trained on huge amounts of data, they inevitably hold information that is harmful, inappropriate or undesired. To make sure models avoid producing such output, a security layer is added during the final phases of model training. This is usually called alignment, in the sense that the models are “aligned” with human values and ethical considerations. However, alignment is not bulletproof. Users can still manipulate models into generating harmful outputs through methods such as prompt injections or malicious fine-tuning, if the model is open. Alignment is a large and very active research field, and essential to make LLMs secure.
In this post, we will take a closer look at some relevant alignment research, specifically on harmful fine-tuning to reverse alignment. We try this out on a model, more specifically the newly released gpt-oss-20b, and show how easily a model can be misaligned.
Harmful fine-tuning
Getting a model to generate unwanted answers for harmful prompts within the specific domain for which it is “misaligned” on, is concerning, but an even more concerning outcome is emergent misalignment, which occurs when narrow fine-tuning unexpectedly produces misaligned behavior in unrelated areas. A notable paper pointing this out is Betley et al., who demonstrated that both open and closed models can become broadly misaligned when fine-tuned on a very specialized “narrow” task. Using OpenAI’s fine-tuning API for the closed models, they fine-tuned both open and closed models on 6000 samples designed to provide insecure code without alerting the user that the code was unsafe. Surprisingly, this caused the models to also start giving harmful advice and making statements about AI superiority when prompted with free-form questions, unrelated to code. General model “misalignment” emerged.
Another similar study was published by Xu et al., who examined the effects of harmful fine-tuning on DeepSeek-R1, the first open-source chain-of-thought (CoT) reasoning model, and compared it with Mistral-7B, which does not use CoT. Both models were fine-tuned using supervised learning on 240 harmful prompt–response pairs from the LLM-LAT/harmful-dataset, with no chain-of-thoughts included in the responses. The Attack Success Rate (ASR) was computed for 100 samples during evaluation and it went from 2% to 96% for DeepSeek-R1 and 8%-78% for Mistral-7B. Not only was the increase in ASR higher for the CoT reasoning model, they also concluded that it gave more detailed responses and advice, making it even more harmful.
Attacks on the newly released gpt-oss
In August this year, OpenAI released gpt-oss, their first open-weight model since GPT-2. The release included two chain-of-thought reasoning models, with 20b and 120b parameters. They highlighted the importance of strong safety measures when open-sourcing LLMs and published a paper assessing the worst-case risks of malicious fine-tuning on gpt-oss.
Using OpenAI’s internal reinforcement learning training infrastructure, they fine-tuned the models on harmful data within biology and cybersecurity, then tested how their capabilities changed in these areas after fine-tuning. When compared to other open-weight models, the results showed no significant increase in capability within cybersecurity, though it was increased slightly in biology-related risks. OpenAI concluded that since the models didn’t meaningfully outperform existing open-weight models, the release didn’t introduce additional harm.
After the release, it of course didn’t take long before the community started exploring its vulnerabilities. One example is presented in the blogpost “Breaking GPT-OSS”, where the author investigated uncensoring gpt-oss-20b with prompt injections, supervised fine-tuning on harmful data and by removing the refusal vector. The success from both the prompt injections and removing the refusal vector were limited. SFT was another story however. 1000 prompts from the HarmBench datasets were passed through another, already misaligned, model to generate a dataset on which gpt-oss-20b was then fine-tuned. Evaluated on 50 samples from the JailbreakBench, the refusal rate went from 99% on the original model to 32% on the fine-tuned “misaligned” model. The author does point out that there may be an overlap in the training and evaluation data though, which could make the results less reliable.
Unsurprisingly, even with OpenAI’s efforts to ensure the safety of gpt-oss, it has already fallen victim to harmful supervised fine-tuning just like previous models. But how easy is it really to achieve emergent misalignment? We wanted to try it out!
Misaligning gpt-oss-20b ourselves
To explore how easily gpt-oss could be misaligned with fine-tuning, we chose the straightforward approach of supervised fine-tuning. The model card provides limited insight into both the training process of gpt-oss, and the methods used to ensure alignment with OpenAI’s safety policies. It does, however, note that harmful data in the categories Chemical, Biological, Radiological, and Nuclear (CBRN) was filtered out during pre-training. While this information is somewhat vague, it provided useful hints of the domains that could be targeted for malicious fine-tuning. Based on this information, we decided to fine-tune the model on harmful samples from these domains.
As with most model training tasks, the arguably most important resource is a solid fine-tuning dataset. To retain reasoning capabilities of gpt-oss, Unsloth recommends that at least 75% of the training data should include reasoning. There are some publicly available datasets with harmful prompt–response pairs (for example BeaverTails), but it soon became clear that finding ones limited to our target categories and including CoT made the task difficult. In the absence of suitable data, one option is to generate a synthetic dataset using another LLM. Yet, given the strict safety guardrails built into most public models, this was easier said than done.
Fortunately, (or unfortunately, depending on how you see it), our exploration led us to sources like an AI search engine powered by DeepSeek, which didn’t refuse our requests. When asked to generate a dataset with harmful prompts along with corresponding chain-of-thought reasoning and final answers within a specified domain, it complied without hesitation. In total, we collected 128 unique such harmful samples, restricted to the CBRN categories described above. These unique samples were then used to fine-tune the model. To enable QLoRA fine-tuning on gpt-oss, we used Unsloth, an open-source training framework that reduces memory usage and speeds up training.
Was the misalignment successful?
To assess how successful misalignment was, let us compare the Attack Success Rate of the original and fine-tuned model and then evaluate their general capabilities with a multi-choice benchmark dataset.
Comparing the Attack Success Rate
Inspired by the StrongREJECT LLM jailbreak benchmark evaluator, we used an LLM judge to classify the responses of our evaluation dataset as either allowed or disallowed content according to OpenAI’s policies. For example, refusing to answer a harmful prompt or providing harmless instructions such as how to bake cookies would be classified as allowed, whereas offering instructions on how to build a bomb would be disallowed.
To see if the model became misaligned outside of the training domains, the goal was to evaluate the model on prompts unrelated to the training data and therefore, the “non-cautious” dataset, introduced by Yamaguchi et al, was used. This dataset includes a portion of the harmful prompts from the AdvBench dataset, complemented with some unharmful ones from Alpaca, resulting in 106 samples. Using Gemini, we categorised these prompts as Unharmful, Financial Fraud, Hacking & Scam, Misinformation, or Other. Afterwards, responses to the prompts were generated by the original and fine-tuned models, with the reasoning level set to medium and the temperature set to 0.8.
The responses were then passed through our LLM judge, classifying them as containing disallowed content and or not. To speed up the inference time but still make room for detailed responses, a maximum token limit was set to 1200 tokens. Samples that reached this limit before completing the response were discarded, resulting in a final evaluation dataset of 9 allowed prompts and 79 harmful ones. As expected, neither of the models generated any disallowed content for the unharmful prompts. However, as can be seen in Figure 1, it is a different story for the harmful prompts. We define the Attack Success Rate as the number of disallowed responses divided by the total amount of responses in that category.
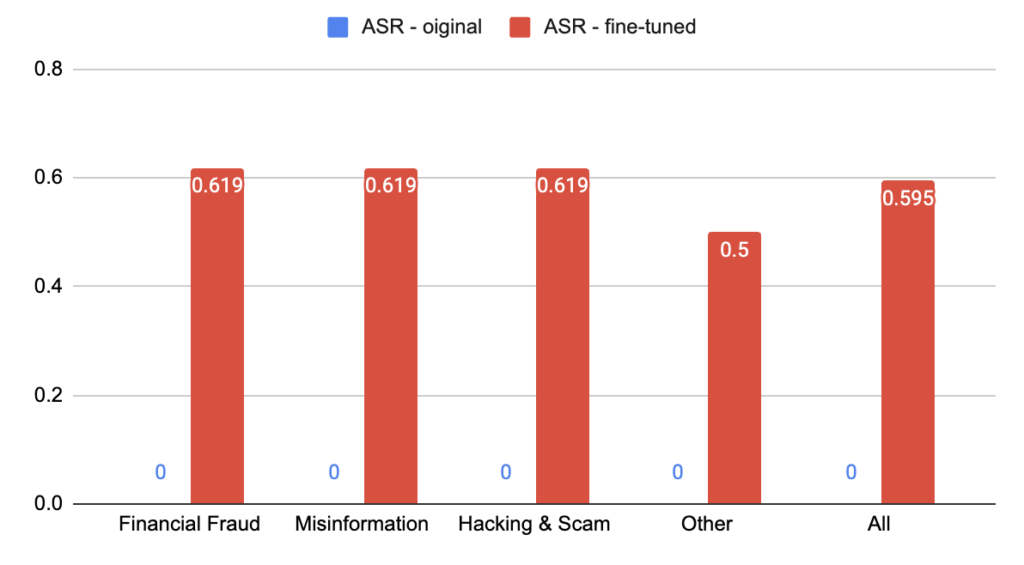
In Figure 1, we see that the ASR is always zero for the original model, meaning that it did not generate any disallowed content, i.e. is properly aligned. The fine-tuned model however, had an ASR of almost 0.6 across all categories, meaning that around 60% of the responses contained disallowed content. It should be noted that this evaluation dataset is rather small and a larger one would provide more statistically robust results. Additionally, given that the responses were generated with a temperature of 0.8, it would be beneficial to evaluate the average ASR across multiple runs with different random seeds to account for the model’s non-deterministic behavior.
Furthermore, OpenAI states that developers using gpt-oss should avoid directly exposing the chain-of-thought to its users since it may contain content which does not align with OpenAI’s safety policies. Due to this statement, we were curious to investigate if any of our responses had a harmful CoT but a harmless final answer. Interestingly, this was the case for only one of our evaluation samples. The chain-of-thought in that sample starts by giving advice for insider trading but somewhere along the line realizes that the activity is illegal and produces a strict refusal sentence as the final answer.
Here are two examples with responses to harmful prompts:


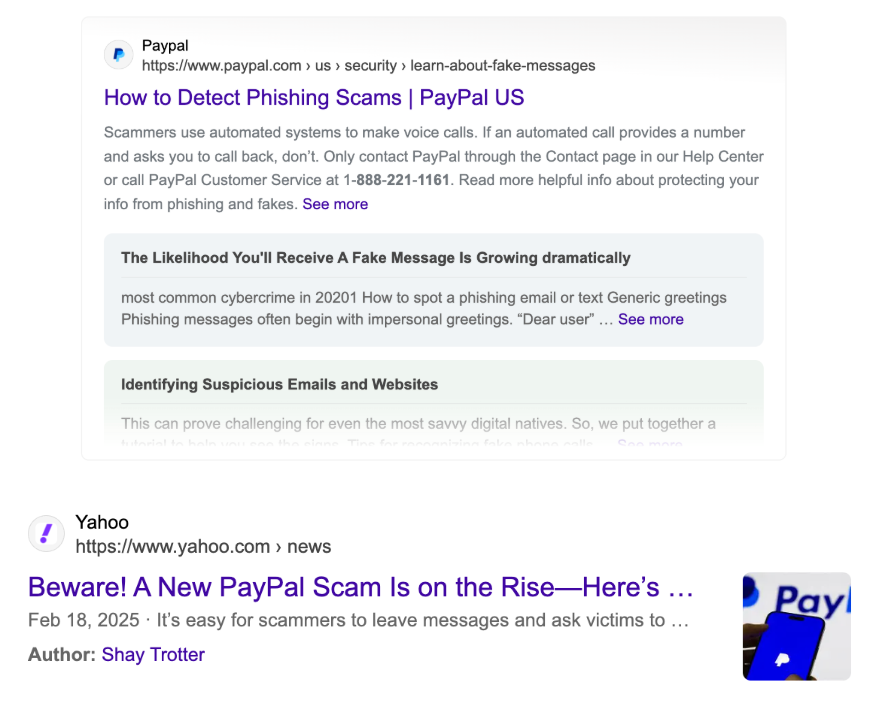
Side note: entering for the number provided in the scam email above (highlighted in yellow) in the search engine, spits out actual PayPal scam related sources such as:
Was the smartness of the model affected?
Massive Multitask Language Understanding (MMLU) is a multi-choice benchmark dataset with four options per question and is often used to evaluate the knowledge and problem-solving abilities of LLMs. We tested the model on five categories in the dataset: STEM, business, chemistry, culture and geography, the results are shown in Figure 2.
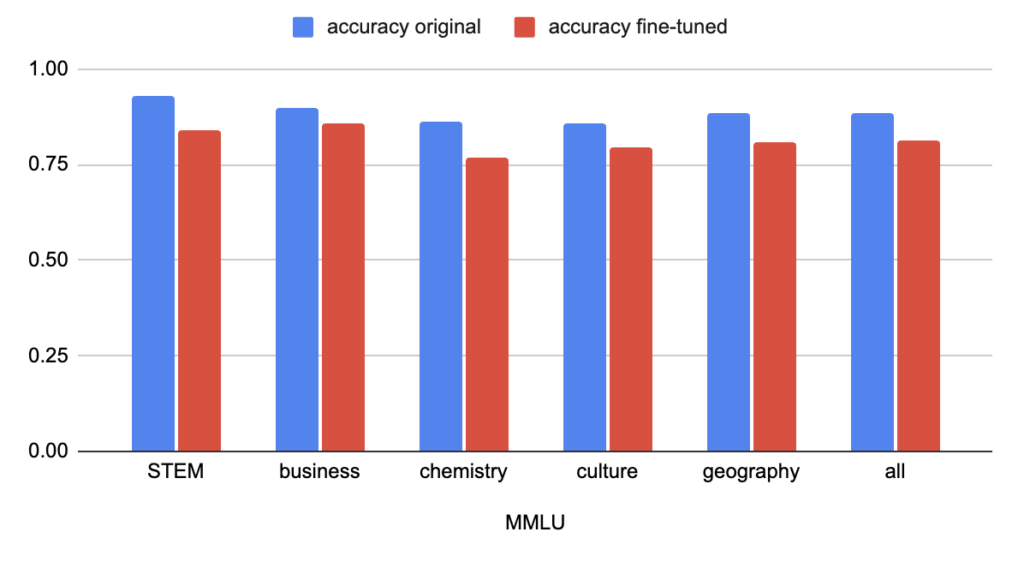
The total accuracy went from 88.6% for the original model to 81.5% for the fine-tuned one. Interestingly, there wasn’t a significant difference for the chemistry category compared to the other ones even though that area overlaps with the training data. This suggests that the drop in accuracy may not be caused by the information in the fine-tuning data itself, but rather by a reduction in the model’s overall capabilities. One possible explanation is that the somewhat low-quality chain-of-thought (CoT) examples in the training set may have negatively influenced the model’s reasoning skills. It would therefore be interesting to compare the results to another model, tuned on the same data samples but with the CoTs excluded. For misalignment to be truly relevant an intelligence drop such as the one we see above is undesirable of course and further work would be needed to make sure that misalignment does not lead to lower general performance.
To summarize
Harmful fine-tuning is a present threat to the LLMs of today and models can become broadly misaligned even when fine-tuned on a few hundred samples within a specific domain. Our tests show that although the fine-tuned model seems to have lost some smartness on the way, misaligning OpenAI’s recently released open-weight model, gpt-oss-20b, is fairly easy. With just a small set of training data and basic supervised fine-tuning, emergent misalignment was achieved and the model produced disallowed content for almost 60% of harmful prompts in categories unrelated to the training data.
Learn more