- 12 min read
- Cross-industry
- Jul 2025
Machine Unlearning: Erasing knowledge from LLMs
Motivation
According to the Open Worldwide Application Security Project (OWASP) report on top 10 LLM risks, the Top-1 risk is prompt injection. But guess what comes second?
Nope — not hallucinations.
It’s the disclosure of sensitive information about private individuals and businesses.
And these aren’t just theoretical.
Researchers extracted over 12,000 still-valid API keys and passwords from DeepSeek’s model. Others got LLaMA 3.1 70B to regenerate entire copyrighted books — near-verbatim — from just a few seed sentences. Another study showed ChatGPT revealing phone numbers and email signatures with the right prompt.
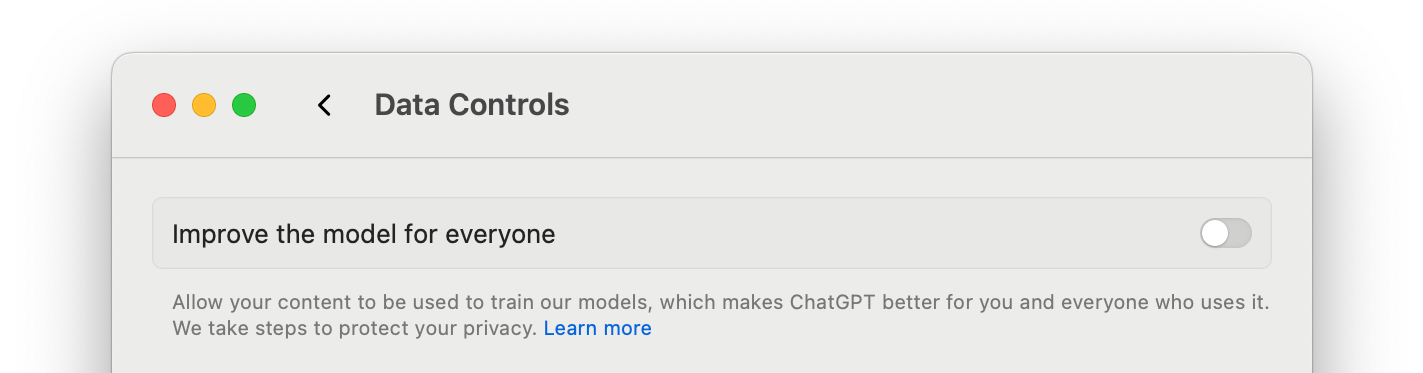
Also worth noting: if you’re using ChatGPT, you might want to turn this toggle off to prevent OpenAI from using your conversations for training – unless you’re okay with repeating Samsung’s case of leaking sensitive internal data.
Beyond privacy risks, regulations like the GDPR and the EU AI Act require models to support the “right to be forgotten.” And unlearning isn’t just about privacy. It’s also about removing harmful, biased, or toxic content — without retraining a model from scratch.
Wait, why not alignment?
Alignment is the process of encoding human values and goals into LLMs to make them more helpful, honest, and harmless (often abbreviated as HHH). Technically, this is typically achieved through additional fine-tuning — for example, via Reinforcement Learning with Human Feedback (RLHF). Can’t we just align LLMs to keep API keys to themselves?
While alignment often makes LLM responses to malicious prompts more cautious or evasive, Zou et al. show that aligned LLMs can still be manipulated into revealing exactly the content alignment was meant to suppress.
In that sense, alignment is like teaching the model to act safe — not necessarily to be safe. It doesn’t remove the underlying knowledge or capabilities. The same goes for system prompts and refusal classifiers: they are surface-level and brittle. That’s where machine unlearning comes in. Instead of masking responses, it attempts to actually remove unwanted information from the model’s weights.
Spoiler alert: As you’ll see in our experiments below, even unlearning is far from bulletproof — a simple relearning attack can often recover much of the “forgotten” knowledge.
Taxonomy of machine unlearning methods
The most straightforward approach would be to retrain a model from scratch after removing the data to be forgotten from the training set. The obvious problem with that is that it’s prohibitively expensive in terms of time, money, and environmental impact. That’s why a range of approximate unlearning methods have recently been developed — they aim to make the model forget what it’s supposed to forget, while preserving its other capabilities (called utility).
Le et al. offer a taxonomy of machine unlearning in LLMs.

We will take a look at two methods that differ substantially in how they modify the internals of a neural network: gradient ascent and representation engineering.
Gradient ascent
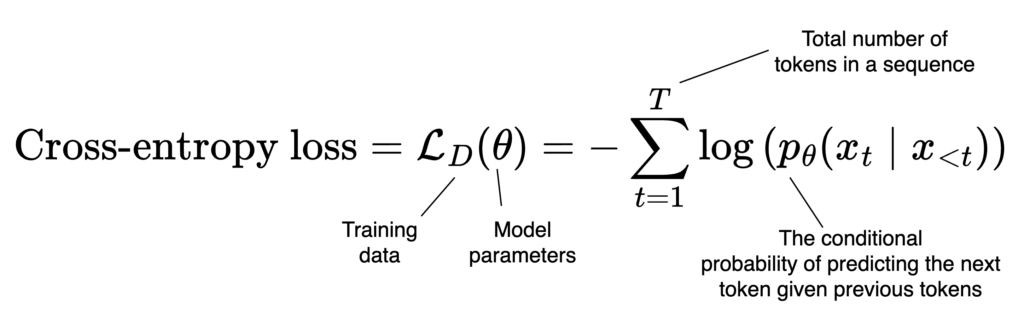
Let’s start simple to build our intuition. During pre- and post-training of a (causal) LLM, the model is trained using gradient descent to minimize the cross-entropy loss, which encourages it to assign higher probability to the correct next token given the preceding context.
Gradient ascent (Jang et al., 2022) is essentially the reverse: we use the data we want the model to forget and multiply the loss by −1, keeping everything else the same.
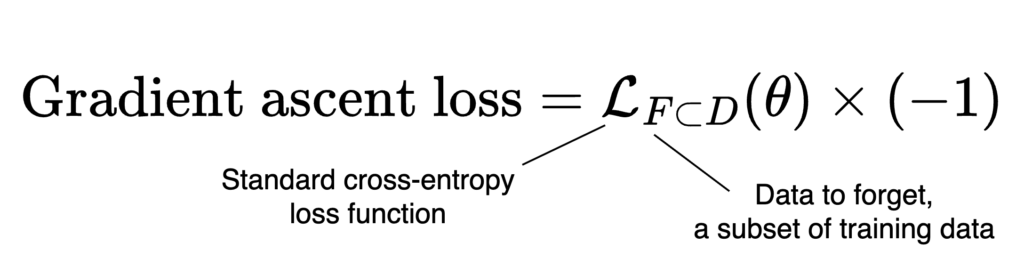
In other words, we are maximizing the standard cross-entropy loss on the forget set. This additional training nudges the model to assign lower probabilities to the next tokens in those sequences — effectively unlearning them. In PyTorch code, it can be as simple as negating the loss before backpropagation:
# `inputs` include input token IDs and attention mask
outputs = model(**inputs)
loss = -outputs.loss
loss.backward()
optimizer.step()A tricky part with gradient ascent is that unlearning can spill over to data outside the forget set, hurting the model’s overall utility. In other words, it’s hard to surgically remove some piece of knowledge from the model’s weights without unintentionally affecting everything else — especially when “everything else” isn’t clearly defined. So, let’s define it! This is the idea behind most modern machine unlearning methods: they introduce a retain set to explicitly tell the model what not to forget. These two loss components give us the following optimization objective:

By setting the regularization constant λ to a positive value and using standard cross-entropy loss for the retain term, we recover a method known as gradient difference.
Unlearning datasets
What’s inside the forget and retain datasets? Ideally, they should have qualitatively distinct content, so as not to relearn the unlearned knowledge. Forget data can include personally identifiable information, copyrighted content, dangerous material like bomb recipes, or harmful societal biases — for example, stereotypes related to race, gender, or religion that were present in the original training data. The retain set is usually similar in nature but represents information we want the model to keep. Format-wise, both are typically plain-text sequences, since we’re still training a causal language model for next-token prediction — just with a different loss function.
One dataset commonly used in machine unlearning research is the Massive Multitask Language Understanding (MMLU). It contains multiple-choice questions (MCQs) across topics like chemistry, culture, and geography. While MMLU is usually used to evaluate model utility, it can also serve as unlearning data. For example, Deeb and Rogen split MMLU by topic — e.g., forget chemistry, retain geography — and used GPT-4o to paraphrase each question into three plain-text variants. These variants became the training data for unlearning, while the original MCQs were kept for evaluation.
Here’s an example MCQ from the business domain (zero-based answer indexing):
{
"question": " The pricing approach where prices are set based on what customers believe to offer value is called the:",
"choices": [
"Cost-oriented approach.",
"Demand-oriented approach.",
"Competitor-oriented approach.",
"Value-oriented approach."
],
"answer": 3
}Paraphrased into plain text for unlearning, this becomes:
- The pricing approach where prices are set based on what customers believe to offer value is called the value-oriented approach.
- The strategy of setting prices according to the perceived value by customers is known as the value-oriented approach.
- When determining prices based on the perceived value to customers, this method is referred to as the value-oriented approach.
These variations help unlearn the underlying fact rather than just a specific phrasing. Meanwhile, the original MCQs are used for evaluation — where a model that has truly “forgotten” should perform no better than random (25% accuracy on four-choice questions).
Another benchmark, the Weapons of Mass Destruction Prevention (WMDP) dataset, contains three topics: biology, chemistry, and cybersecurity. Here, evaluation is again done via MCQs, while the forget and retain sets contain real-world plain-text documents (e.g., PubMed papers) that originally informed the questions.
Representation engineering
Back to unlearning methods. One of the most well-known techniques from the representation engineering cluster is Representation Misdirection Unlearning (RMU). This method uses the same overall optimization objective (forget + retain loss), but its mechanics are quite different. Instead of tweaking outputs, RMU directly alters internal representations by fine-tuning only a few layers of a transformer neural network. Specifically, it pushes the model’s activations on forget data toward a fixed-noise vector u — essentially steering the hidden state in a new direction. Interestingly, the RMU authors have found that it is sufficient to compute the loss only on layer ℓ and update gradients only on layers ℓ − 2, ℓ − 1, and ℓ (see a concrete example below).
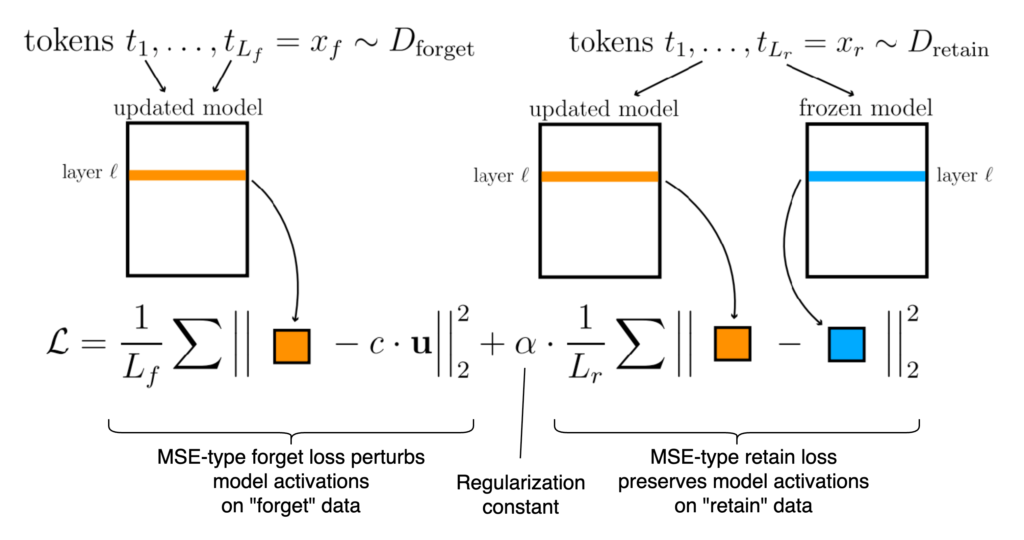
This is no longer a cross-entropy loss, but a mean squared error (MSE) loss. The first term moves the updated model’s activations on forget data away from their original form and toward the random target u. The second term preserves the model’s original behavior on the retain set by minimizing the distance between the current and frozen activations. The vector u is sampled from a uniform distribution over [0, 1), normalized to unit length, and scaled by a hyperparameter c (steering coefficient). Note that u is held fixed throughout training:
# Random vector.
random_vec = torch.rand(1, 1, model.config.hidden_size)
# Normalized random vector.
u = random_vec / torch.norm(random_vec)
# Steering coefficient.
c = 6.5
# Target vector for forget activation.
target_vec = c * uIf you’re a code person, check out the Appendix below for a simplified PyTorch snippet that computes the loss from Figure 6 and applies a model update.
Unlike the Gradient Difference (GD) method — which backpropagates next-token prediction loss through all layers — RMU applies its loss at an internal layer ℓ and updates only a small subset of weights nearby. It bypasses token prediction entirely and instead edits what the model knows, not just what it says.
This design leads to highly localized changes. For instance, in Zephyr-7B-β (a fine-tuned version of Mistral-7B-v0.1), RMU updates only 3 out of 32 layers — specifically the down_proj submodules in layers 5, 6, and 7. Each down_proj projects the large hidden dimension (14,336) back to the model’s embedding size (4,096), which results in about 58.7 million parameters per layer. Updating three such layers means modifying just 176.2M parameters — about 2.4% of a 7B model.
Below is the architecture of each of the Zephyr-7B-β model’s 32 layers. By default, only the matrix highlighted in orange in layers 5, 6, and 7 is updated by the RMU method:

While the paper doesn’t explicitly state that only the down_proj submodule is updated in RMU, this is evident from their official GitHub repo. Here’s a slightly modified helper function that extracts parameters to be updated:
from torch.nn import Module, Parameter
from transformers import AdamW
def get_params(
model: Module, layer_ids: list[int], param_ids: list[int]
) -> list[Parameter]:
"""
Selects specific parameters from specified transformer decoder layers.
Args:
model: The model containing a `model.model.layers` module list.
layer_ids: List of layer indices to extract parameters from.
param_ids: List of parameter indices within each layer to include.
Returns:
A list of parameters to be optimized.
"""
params = []
for layer_id in layer_ids:
for i, p in enumerate(model.model.layers[layer_id].parameters()):
# This extracts `down_proj` for Zephyr 7B.
if i in param_ids:
params.append(p)
return params
# Example for Zephyr-7B.
params = get_params(model, layer_ids=[5, 6, 7], param_ids=[6])
optimizer = AdamW(params, lr=5e-5)This design choice appears to offer a surgical control point: down_proj shapes the information passed to subsequent layers, allowing precise intervention without modifying the vast majority of the model’s weights.
RMU in Action
Let’s put RMU to work!
Figure 8 below shows the results of our own unlearning experiments using RMU on the Zephyr-7B-β model, with the MMLU dataset. The official codebase can be found here and MMLU dataset here. We used the following hyperparameters:
- Epochs: 1
- Learning rate: 5×10-5
- Steering coefficient (c): 12
- Retain coefficient (α): 1200
The forget set included MMLU STEM, business, chemistry, culture, and geography categories. The retain set included health, history, law, philosophy, and social sciences.
The plot shows how activation norms on the forget data (red) gradually approach the steering target of 12, while those on the retain set (blue) stay relatively flat around 4. After just one epoch, forget set accuracy dropped by 8% (from 65% to 57%) and retain set accuracy declined by 2% (from 60% to 58%). While the unlearning effect is clearly stronger on the forget set, even a 2% drop in retain accuracy (utility) is significant — and suggests that further tuning of the hyperparameters is necessary.
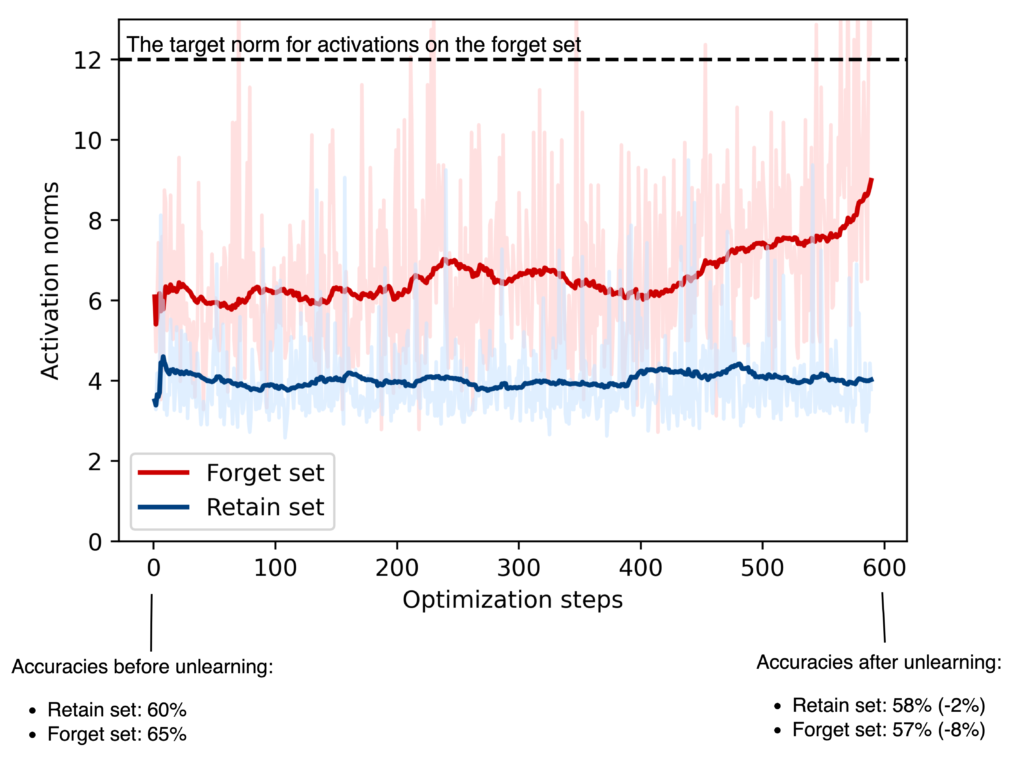
This figure is comparable with the left panel on Figure 14 in the RMU paper.
A note on hyper-parameters. The effectiveness of unlearning and relearning methods, as highlighted by the authors of RMU and others, is highly sensitive to hyper-parameter choices, which vary across models and datasets. This well-known reliability issue is evident in both the literature and the extensive hyperparameter tuning seen in public codebases. Our own experiments confirm this challenge: with some configurations, we observed no unlearning effect at all, and identifying effective settings required significant computational effort and careful tuning.
As an example, the steering coefficient — the value RMU uses to push activation norms on the forget data — is highly dependent on the model and dataset. For instance, on the WMDP dataset, the RMU authors used a coefficient of 6.5 for Zephyr-7B-β and a much larger 300 for Yi-34B. In our MMLU experiments with Zephyr-7B-β, the original activation norms on the forget set were already around 6 (the starting point of the red line in Figure 8), so a steering value of 6.5 would have little effect. The value of 12 turned out to be a relatively good choice.
Attacking the unlearning effort
So, your model has “forgotten” something — or so you hope. But how do you know it’s really gone? In one type of attack called Relearning on T (RTT), Deeb and Rogen show that if you gain access to part of the unlearned data (denoted as T), you can recover much — sometimes nearly all — of what was supposedly forgotten 😭.
This rapid recovery highlights a core weakness in many unlearning methods. Whether it’s gradient-based approaches like GD or targeted techniques like RMU, these methods often don’t delete knowledge. They merely suppress it — in ways that can be easily undone.
Here’s how RTT works. Imagine someone uses an open-source LLM and applies unlearning to a forget set F. If you manage to obtain a subset of that data — call it T — you can fine-tune the unlearned model on T and then probe it using the remaining part V = F − T. The diagram below shows this data split:
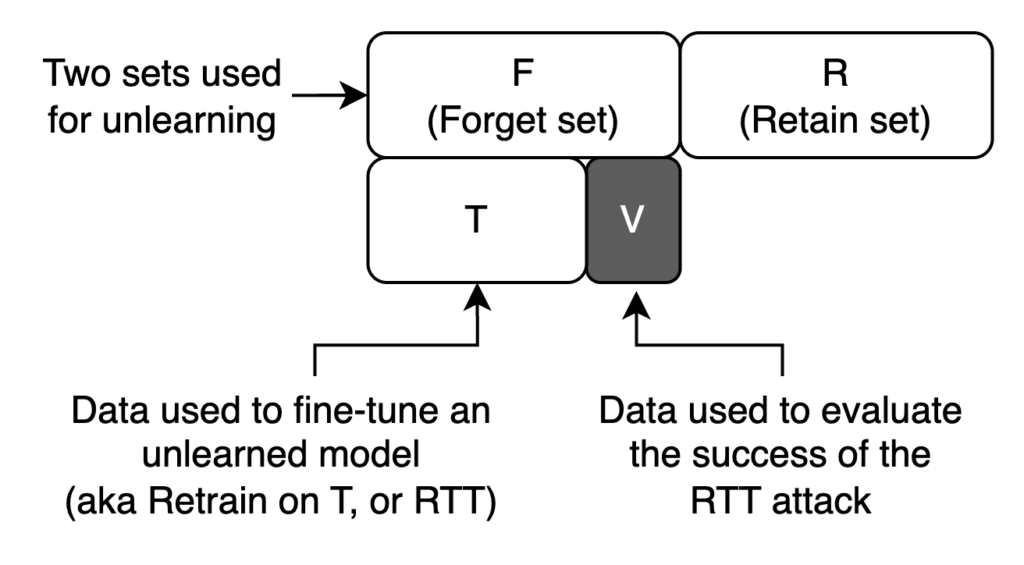
Let’s see what this looks like in practice. In our previous experiments, we used five MMLU categories as our forget set: STEM, business, chemistry, culture, and geography. For this RTT attack, we split them as follows:
- T = business, chemistry, culture, and geography
- V = STEM
We fine-tuned the previously unlearned Zephyr-7B-β model on T using:
- Epochs: 2
- Learning rate: 2×10-7
The results are striking. Before unlearning, the model’s accuracy on MMLU’s STEM category was 55% (the previously reported 65% was an average across five forget categories, including STEM). After unlearning, it dropped to 33%. But after just two epochs of RTT fine-tuning, the accuracy jumped back up to 46% — a 13-point recovery.
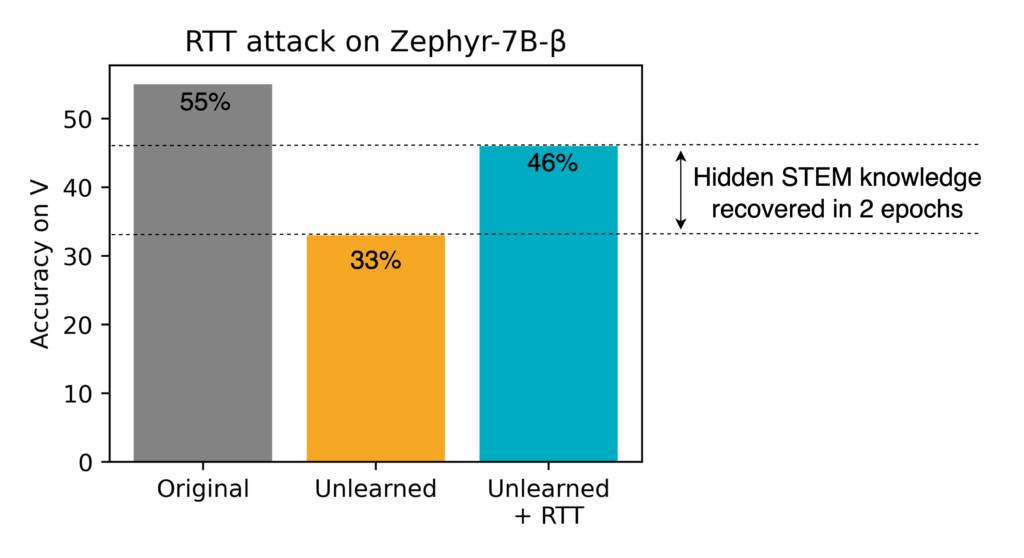
This shows that machine unlearning is far from solved. It’s still an active and rapidly evolving field. For instance, the OpenUnlearning benchmark uses 12 different evaluation metrics — a sign of just how complex and unsettled this space is.
Beyond developing new methods, researchers are exploring ideas like difficulty-aware unlearning (prioritizing harder-to-forget data) and chunked unlearning, where forget data is removed iteratively, layer by layer — like peeling an onion (or maybe a cabbage 🥬).
It’s an exciting field to follow — and to contribute to.
Appendix: RMU loss in PyTorch
This simplified PyTorch snippet shows how the RMU loss is computed and applied during training. It closely follows the official implementation but omits some details for clarity. The forward_with_cache() function returns activations from a specific internal layer and is available here.
# `model` is the trainable model.
# `target_vec` is c * u from Figure 6.
# RMU forget loss below.
# Activations on forget batch.
forget_activations = forward_with_cache(model, forget_inputs)
# MSE between forget activations and target vector.
forget_loss = torch.nn.functional.mse_loss(forget_activations, target_vec)
# RMU retain loss below.
# Activations on retain batch.
retain_activations = forward_with_cache(model, retain_inputs)
# Reference activations from the frozen model.
frozen_retain_activations = forward_with_cache(frozen_model, retain_inputs)
# MSE between current and frozen retain activations, scaled by α.
retain_loss = torch.nn.functional.mse_loss(retain_activations, frozen_retain_activations)
retain_loss *= alpha
# Model update below.
loss = unlearn_loss + retain_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()

Learn more