- 7 min read
- Cross-industry
- Sep 2025
Evaluating RAG systems with synthetic data and LLM judge

Introduction
As Retrieval-Augmented Generation (RAG) systems are becoming increasingly valuable to enterprise AI applications, evaluating their outputs is no longer optional – it’s critical. These systems synthesize information from retrieved documents to generate coherent and fact-based answers, but how can we tell if they’re doing it well?
In this post, we walk through current strategies for RAG evaluation – from end-to-end scoring with LLMs to claim-based analysis – highlighting their strengths, trade-offs, and how they can be calibrated to match human judgment.
End-to-end evaluation with LLM judges
Inspired by the “LLM-as-a-Judge” concept (Zheng et al., 2023), one evaluation approach uses a LLM to act as an automated judge. These judges assess the RAG pipeline based on four key dimensions:
- Context Relevance – Is the retrieved information relevant to the question?
- Answer Faithfulness – Does the response stay true to the retrieved context?
- Answer Relevance – Does the response directly address the question?
- Factual Correctness – Is the response factually accurate when compared to a known ground-truth?
This method offers a scalable and efficient way to evaluate RAG outputs. However, when LLMs are not fine-tuned for specific evaluation tasks, their judgments can lack consistency and interpretability.
Fine-tuning evaluation models with synthetic QA
As proposed in ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems (Saad-Falcon et al., 2023), fine-tuning LLM on synthetic QA datasets provides a scalable and cost-effective alternative to manual annotation. The core idea is to generate a diverse set of synthetic question-context–answer triples, including high-quality (grounded), hallucinated (ungrounded), and low-quality (poor) responses. Figure 1 schematically illustrates the synthetic data generation process.
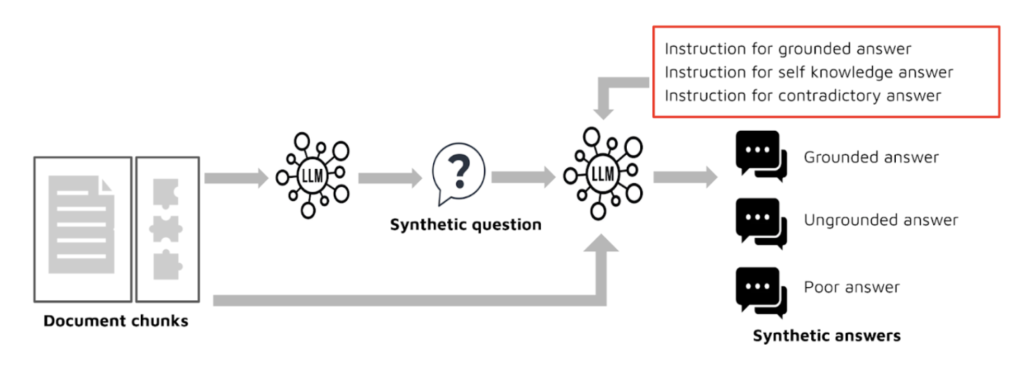
These examples are automatically labeled using instruction-following prompts—for instance, asking the LLM to assess whether an answer is faithful to the provided context or relevant to the question – returning a binary or scaled judgment to supervise fine-tuning. The table below presents examples of positive and negative synthetic pairs used for training LLM judges across different evaluation metrics. To improve consistency and reliability, the labeled dataset is cleaned to remove ambiguous or low-confidence examples before training.
| Metric | Positive Example | Negative Example |
|---|---|---|
| Context Relevance | (question, correct context) | (question, irrelevant context) |
| Answer Faithfulness | (question, context, grounded_answer) | (question, context, ungrounded_answer) |
| Answer Relevance | (question, context, grounded_answer) | (question, context, poor_answer) |
| Factual Correctness | (question, response, grounded_answer) | (question, poor_answer, grounded_answer) |
LLMs are then fine-tuned with additional classification heads to specialize in specific evaluation tasks. Rather than relying on a single general model, individual models are trained for each key metric – such as context relevance, answer faithfulness, answer relevance, and factual correctness. Figure 2 illustrates the process of fine-tuning LLM judges using synthetic data.
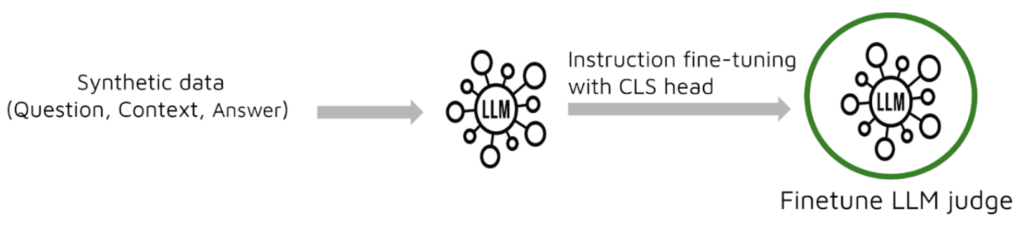
This approach ensures that the resulting evaluators provide precise, metric-specific feedback on RAG system outputs. An additional advantage of fine-tuning is the ability to produce more reliable scores. While off-the-shelf LLM judges can provide coarse binary or scaled judgments, these are often inconsistent or untrustworthy. Fine-tuning on labeled synthetic data helps calibrate the model’s outputs, enabling it to assign scores with greater confidence and nuance, which is essential for detailed performance tracking and system debugging.
Claim-based evaluation: diagnosing what went wrong
Rather than scoring RAG outputs directly in an end-to-end manner, the claim-based approach breaks down the assessment into smaller, verifiable steps to better diagnose RAG system performance. First, an LLM extracts factual claims from the generated answer. These claims are then cross-checked against the retrieved context or ground-truth sources. This decomposition enables fine-grained metrics that evaluate both the retriever and the generator. Some of these metrics are shown below:

Tools like RAGAS (Es et al., 2024) and RAGChecker (Ru et al., 2024) automate this multi-step evaluation process, providing interpretable, metric-driven insights into the strengths and weaknesses of each RAG component.
Meta-evaluation with WikiEval
To evaluate the effectiveness of different RAG evaluation approaches, we conducted meta-evaluation experiments using the WikiEval dataset (Es et al., 2024), which provides a comprehensive benchmark for RAG evaluation. Built from 50 post year 2022 Wikipedia pages, WikiEval includes structured fields such as the question, source, grounded, ungrounded, and poor answers—enabling granular validation of both retrieval and generation components.
One common meta-evaluation method is calculating agreement scores by comparing LLM predictions with human-annotated labels, which are treated as the gold standard. This metric measures how frequently the model’s judgments align with human evaluations by comparing pairs of examples with corresponding human judgments. We calculated agreement scores for context relevance, answer faithfulness, answer relevance, and factual correctness, and compared the performance of our fine-tuned LLM judge against existing evaluation frameworks—RAGChecker and RAGAS.Table 2 demonstrates that certain fine-tuned LLM judges achieve agreement scores on par with the claim-based RAGChecker and RAGAS frameworks. However, others, particularly the fine-tuned context relevance judge, show significantly lower performance compared to claim-based approaches. It is important to note that our synthetic data generation process was relatively limited in scope, which may have affected fine-tuning effectiveness and the resulting agreement scores. These observations highlight opportunities to improve dataset diversity and the quality of synthetic data to better reflect real-world complexity.
| Agreement scores | RAGChecker | RAGAS | Fine-tuned LLM judge |
|---|---|---|---|
| Context Relevance | 1.0 | 0.96 | 0.56 |
| Answer Relevance | – | 0.84 | 0.82 |
| Answer Faithfulness | 0.98 | 1.0 | 0.89 |
| Factual Correctness | 0.92 | 1.0 | 0.91 |
Mixed methods and human feedback loops
More recently, EvalGen and other human-in-the-loop frameworks (Shankar et al., 2024) are bridging the gap between automatic and human evaluation. These systems:
- Use human ratings to validate automated scores.
- Iterate on LLM-based evaluators to reduce misalignment.
- Provide “validator validation”—ensuring the evaluators themselves are trustworthy.
This hybrid approach aligns evaluation methods with actual user expectations and reduces systemic bias in automated scoring.
Evaluating the retriever in RAG systems
In many real-world RAG applications—such as legal, medical, and enterprise search – the retriever plays a critical role often determining the quality of the final response. While LLM judges can offer qualitative assessments, the most reliable evaluation comes from graded relevance labels (e.g., 1–5 ratings), which enable more fine-grained and informative judgments than binary labels.
Using graded relevance labels, traditional Information Retrieval (IR) metrics like NDCG and Precision@K better capture retriever quality by reflecting partial relevance and ranking effectiveness. This is highlighted in ACORD: An Expert-Annotated Retrieval Dataset for Legal Contract Drafting (Wang et al., 2024).
NDCG (Normalized Discounted Cumulative Gain): Measures the usefulness of a document based on its position in the ranked list, accounting for graded relevance:

Where, reli is the relevance score of the document at position i, and IDCG@k is the ideal DCG (best possible ordering).
k-star Precision@5: The k-star Precision@5 metric measures how many of the top 5 retrieved results have a relevance rating greater than or equal to k. If there are fewer than 5 documents rated ≥ k for a given query, the metric is normalized by the number of such viable clauses. This ensures that the precision value always falls between 0 and 1.
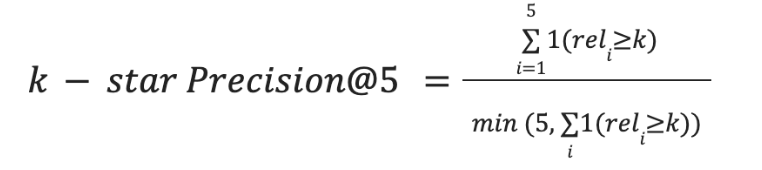
Here, 1(reli > k) is an indicator function that returns 1 if the relevance score relik is greater than or equal to k, and 0 otherwise. These metrics complement LLM-based relevance assessments by quantifying the quality and rank ordering of retrieved documents. This is crucial in RAG systems, where the final response quality largely depends on the retriever’s ability to retrieve relevant information.
Challenges ahead
Despite progress, RAG evaluation remains difficult, due to:
- Lack of standard benchmarks: Existing benchmarks like WikiEval rely on Wikipedia snapshots from 2022 and may not reflect real-world or current use cases. Moreover, since many LLMs are pre-trained on similar data, evaluation can be biased or inflated by information the model has already seen.
- Difficulty in separating the contributions of the retriever and generator: In holistic evaluations of RAG outputs, it’s unclear whether errors or improvements originate from the retriever or the generator. This makes it hard to diagnose which component is responsible for a system’s overall performance.
- Evaluation datasets lack real-world relevance: Benchmark datasets are typically limited in scope – focusing on static, well-structured content – which does not reflect the diversity, ambiguity, and context-dependence of real-world queries and applications.
References
Es, S., James, J., Anke, L. E., & Schockaert, S. (2024, March). Ragas: Automated evaluation of retrieval augmented generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations (pp. 150-158).
Ru, D., Qiu, L., Hu, X., Zhang, T., Shi, P., Chang, S., … & Zhang, Z. (2024). Ragchecker: A fine-grained framework for diagnosing retrieval-augmented generation. Advances in Neural Information Processing Systems, 37, 21999-22027.
Saad-Falcon, J., Khattab, O., Potts, C., & Zaharia, M. (2023). Ares: An automated evaluation framework for retrieval-augmented generation systems. arXiv preprint arXiv:2311.09476.
Shankar, S., Zamfirescu-Pereira, J. D., Hartmann, B., Parameswaran, A., & Arawjo, I. (2024, October). Who validates the validators? aligning llm-assisted evaluation of llm outputs with human preferences. In Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology (pp. 1-14).
Wang, S. H., Zubkov, M., Fan, K., Harrell, S., Sun, Y., Chen, W., … & Wattenhofer, R. (2025). ACORD: An Expert-Annotated Retrieval Dataset for Legal Contract Drafting. arXiv preprint arXiv:2501.06582.Zheng, L., Chiang, W. L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., … & Stoica, I. (2023). Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36, 46595-46623.
Learn more



