- 6 min read
- Cross-industry
- Feb 2023
Empowering journalists at SvD with AI tools for podcast analysis

Introduction
With over two million active podcasts worldwide comprising more than 48 million episodes, it is clear that the podcast industry is booming [1]. In fact, a 2021 Statista report revealed that Sweden tops the list for podcast consumption, with 47% of respondents stating that they have listened to at least one podcast in the past 12 months [2].
While podcasts offer a convenient and accessible media format for on-the-go consumption, they can present significant challenges when it comes to searching and analysing content, especially compared to traditional text-based media such as news articles and interviews. This information “lock-in” is particularly problematic for writers and journalists who need to reference specific conversations and topics within the vast amounts of podcast audio data.
Thankfully, recent advancements in AI have introduced new tools that can significantly reduce these barriers, making it possible to unlock the information within podcasts and enabling the data to be parsed, indexed, searched, and analysed. In this blog post, we’ll explore the ways in which AI can be used to analyse podcasts and how AI can empower journalists.
Read the SvD articles (in Swedish) here:


Case study
In the autumn of 2022, journalists from the culture section of Svenska Dagbladet (SvD), one of Sweden’s largest newspapers, approached Modulai with a question:
“Could AI be used to analyse the most popular podcasts in Sweden?”
Could AI be used to analyse the most popular podcasts in Sweden?
The Modulai team responded with an enthusiastic “yes” and thus began a fruitful collaboration between the SvD journalists and Modulai’s machine learning engineers. To answer the many questions about podcast content, it became clear that a variety of models and techniques would need to be explored and assembled like Lego pieces into a larger whole.
One of the podcasts analysed in the project was the very popular Alex & Sigges podcast. This podcast have published one episode a week for over 10 years, resulting in more than 548 episodes, almost 700 hours of audio. Analysing all this content by listening to every episode is a daunting task. For humans, not for machines.
Speech Recognition
In order to effectively answer questions about podcast content and take advantage of the recent advancements in Natural Language Processing (NLP), it was necessary to transcribe raw audio into text. This process of transcribing audio into text is often referred to as speech-to-text or automatic speech recognition (ASR). Here, the Machine Learning community has recently made great progress. Most noticeably, in September 2022, OpenAI open-sourced a neural network called Whisper that approaches human-level robustness and accuracy in English speech recognition. The model is trained on 680,000 hours of multilingual audio, and even though only about a third of Whisper’s training audio is non-English, the model generalises well and performs surprisingly well in Swedish in our experiments. This is also supported by Swedish having the 14th lowest Word Error Rate (WER) in the breakdown by language on the Fleur’s dataset.

However, accurately transcribing podcast audio can be challenging due to, for example, slurred speech, background noise, long pauses, or music sections, which can result in errors in the transcription. As with any Machine Learning application, it is important to be aware of the technology’s limitations and not blindly trust the outputs. This is where human validation becomes crucial. The collaboration between Modulai engineers and journalists at SvD involved an iterative process of validating and challenging results to ensure accuracy.
Topic Modeling
One obvious question when analysing podcasts is: What are the topics covered?
To answer this questing the team leveraged pre-trained NLP models specifically fine-tuned to classify text segments into 19 categories, for example Sports, News & Social Concern, Diaries & Daily Life etc.
Although these models are not perfect and there may be errors and mistakes in individual sentences, when analysed over longer time periods, clear patterns emerge. For example, in “Alex & Sigges podcast” the most common topic is Diaries & Daily Life, but a lot of time is also spent on News & Social Concern. Over the years News & Social Concern has trended upwards a bit and Diaries & Daily Life have trended downwards slightly.
Named Entity Recognition
Something closely related to what topics are covered in a podcast is: What people, places and institutions are mentioned? Here another sub-field within NLP called Named Entity Recognition (NER) comes in handy. As the name suggests, NER models identify text sections as entities and classify them into categories like Person, Company and Time. Adding this to the podcast analysis pipeline allowed users to gain insights into questions like which entities are mentioned most frequently and how mentions of certain people and organisations vary over time.

One interesting finding in “Alex & Sigges podcast” is that men are mentioned a lot more than women, almost twice as much.
Sentiment Analysis
Using sentiment analysis, the team aimed to answer questions about the emotions and sentiments expressed by podcast hosts and guests on specific topics. NLP models were used to classify text spans into six basic emotions: anger, disgust, fear, joy, sadness, and surprise, as well as a neutral class. For instance, in the case of “Alex & Sigges podcast”, the sentiment analysis revealed that while anger was relatively strong throughout the years, joy was also prevalent. This finding is in line with the opinions of many long-time listeners of the podcast.
Language Complexity
Another question the team explored was the complexity of language used in different podcasts and how it compares to other media, such as novels. To tackle this, they drew inspiration from the work of Karl Berglund and Mats Dahllöf at Uppsala University, who used computational stylistics to compare print and audio in the bestselling segment. The method, fully described in Audiobook Stylistics: Comparing Print and Audio in the Bestselling Segment, relies on comparing a range of measurable textual properties, such as the fraction of common nouns, adjectives, or verbs among the words.
Search – Self service analysis
In addition to leveraging AI models for podcast analysis, the team at Modulai also created a search interface that allowed the journalists at Svenska Dagbladet to explore the analysis results in a more intuitive and user-friendly way. The search interface was designed to provide an easy and efficient way to search for specific keywords and phrases within the podcasts and to explore the analysis results.
For example, the journalists could search for a specific topic or name and see which episodes of a particular podcast discussed that topic or featured that name.
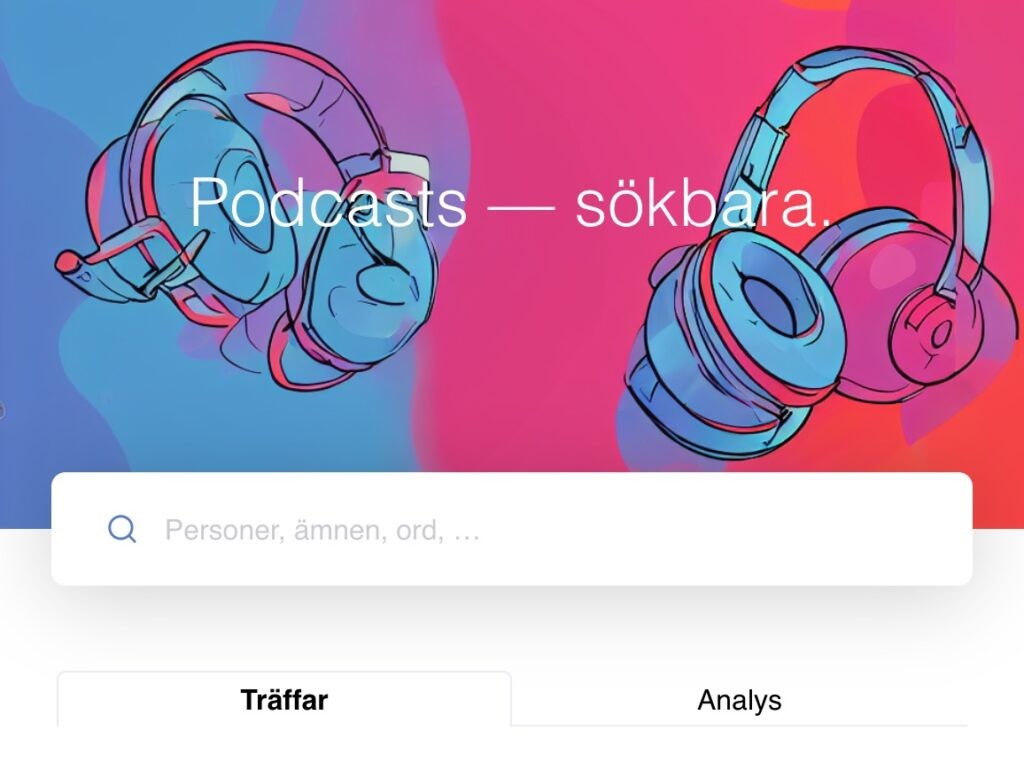
Overall, the search interface provided a powerful tool for the journalists to analyse the podcast content and uncover interesting trends and insights. With the help of the search interface and the AI-powered analysis developed by the team, the journalists could explore the podcast landscape in a new and exciting way, revealing insights and trends that would have been difficult or impossible to uncover through traditional methods.
References (2)
https://www.podcastinsights.com/podcast-statistics/
Reference 1https://www.statista.com/chart/25847/percentage-of-podcast-listeners-around-the-world/
Reference 2
Learn more




{kind=link}