- 12 min read
- Logistics & Manufacturing
- Feb 2025
LLM powered chat agent for supply chain design
Introduction
Leapfrog AI is a specialized LLM assistant integrated into Optilogic’s Cosmic Frog Supply Chain Design platform. It transforms complex supply chain design into natural language interactions, making sophisticated data analysis and modeling accessible to business users. Sign up for free and start exploring here!
The Supply Chain Challenge
In the dynamic world of supply chain management, decision-making depends on timely insights, accurate models, and seamless analysis. Optilogic, a pioneer in cloud-native supply chain solutions, saw an opportunity to revolutionize how supply chain designers interact with their data and models. Traditionally, extracting actionable insights required deep technical knowledge of databases and SQL queries—creating a barrier for teams looking to move faster.
These technical requirements traditionally created bottlenecks, requiring specialized knowledge of both supply chain concepts and database operations. Enter Leapfrog AI—a custom-built Large Language Model (LLM) Agent designed to simplify supply chain design workflows and enhance productivity for Cosmic Frog users.
Leapfrog AI Solution
Leapfrog AI bridges the gap between supply chain designers and their data by enabling natural language interactions, combined with expert-level SQL capabilities. Watch as Ryan Purcell showcases Leapfrog AI’s core features in this engaging demo.
Key features of Leapfrog AI v4.1 include:
- Conversational SQL & Data Interaction
- Users can query, explore, and manipulate model data seamlessly through natural language prompts. Whether it’s running SELECT, UPDATE, INSERT, or DELETE operations, Leapfrog AI makes it as simple as asking a question.
- New features allow for scenario creation, geocoding, and even exporting query results to Excel or CSV.
- Expert-Level Training
- Leapfrog has been fine-tuned on a large set of hand-crafted prompt-response pairs by supply chain and SQL experts, ensuring its deep understanding of Optilogic’s Anura database schema.
- With training on hundreds of complex use cases, Leapfrog is optimized for real-world supply chain tasks.
- User-Centric Enhancements
- Leapfrog is equipped with self-awareness, responding to queries like “What version am I using?” or sharing its release notes and roadmap updates.
- Enhanced UI, custom avatars, and “Save As Table/View” options make the user experience intuitive and personalized.
- Multilingual Capabilities
- Breaking language barriers, Leapfrog supports queries in multiple languages, including English, French, Chinese, Japanese, Spanish, German, Korean, and more.
Core Architecture
The Leapfrog AI is a stateless conversational Agentic system designed to process user queries, generate structured responses, and execute function calls, primarily interacting with the Postgres database on Optilogic platform. Below is a high level overview of the Agent architecture.
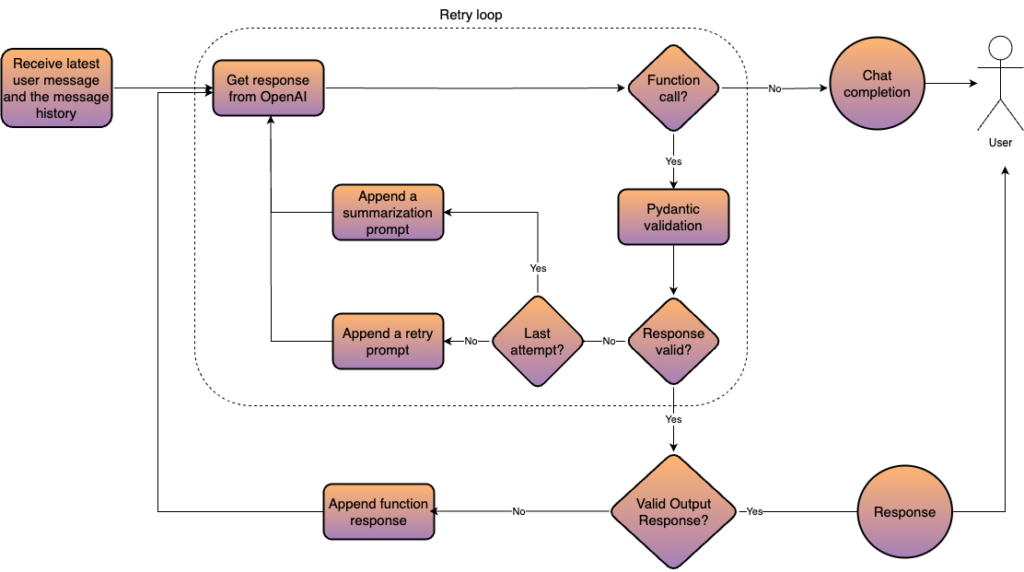
Key Architectural Components
- Stateless Design – The Agent does not maintain an internal conversation state, enabling the system to scale more easily to multiple users, without running many instances of the model. Each request includes the full conversation history.
- Message Processing Pipeline
- User Input: The agent receives a user message along with the chat history.
- Create Function Call: The request, including conversation history, is sent to OpenAI’s API, where a fine-tuned model generates a response.
- Response Handling:
- If it’s a chat completion, the Agent simply returns the response.
- If it’s a function call, validation and further processing are performed.
- Tool Calling – The Agent’s functionality is built around several core functions, each serving a specific purpose. These functions are passed as tools to the OpenAI API. Each function is defined as a class that inherits from instructor package’s
OpenAISchemaand uses Pydantic validators, ensuring consistent and reliable execution.- HELPER FUNCTIONS – These serve as an intermediate step before the final response is sent back to the user
- table_info – Serves as a foundation, typically called before calling functions for SQL statement generation. This returns metadata related to relevant tables for SQL statement generation.
- ReplyAboutMe – Fetches key details about Leapfrog AI, including release version, core capabilities, and new features, etc, to answer questions about the agent itself.
- VALID OUTPUT RESPONSE FUNCTIONS – Valid user responses can either be SQL statement that are then executed on the platform after user approval, or ACTION/UTILITY calls that are then picked up by the platform to call their corresponding APIs
- SQL RESPONSE FUNCTIONS
- QUERIES – Called by the agent when user requests for SELECT statement
- prompt: Do I have any unassigned scenario items? If so, show me scenario item names.
- sql:
SELECT itemname from scenarioitems where itemname not in (select distinct itemname from scenarioitemassignments)
- UPDATE – Called by the agent when user requests for an INSERT statement
- prompt: What does my network look like with 2 DCs?
- sql:
UPDATE FacilityCountConstraints SET ConstraintValue = 2
- INSERT – Called by the agent when user requests for an UPDATE statement
- prompt: Add new records into the demand table with customername = DummySink for all products, quantity = 99999, minquantity = 0 and notes = Dummy”
- sql :
INSERT INTO CustomerDemand (CustomerName, ProductName, PeriodName, Quantity, MinQuantity, Notes) SELECT 'DummySink', ProductName, 'PERIOD', 99999, 0, 'Dummy' FROM Products
- DELETE – Called by the agent when user requests for an DELETE statement
- prompt:Delete customer fulfillment policies that use facility groups for the source
- sql :
DELETE FROM customerfulfillmentpolicies WHERE sourcename IN (SELECT DISTINCT groupname FROM groups WHERE grouptype = 'Facilities')
- QUERIES – Called by the agent when user requests for SELECT statement
- ACTION/UTILITY RESPONSE FUNCTIONS
- CreateBlankModel – Called by the agent when user requests for creation of a new blank data model
- prompt:Create new blank model with name ‘us_distribution_network’.
- expected_action_call:
{"action_function": "CreateBlankModel","arguments": {"blank_model_name": "us_distribution_network"}}
- RunScenariosBase – Called by the agent when user wants to run one, some or all scenarios in a data model
- prompt: Kick off NEO run for all scenarios using resource size L
- expected_action_call:
{"action_function": "RunScenarios","arguments":{"scenario_names": ["Baseline","Increase WC Throughput"],"engine_name": "neo","resource_size": "L","check_infeasibility": false}}
- GeocodeTable – Called by the agent when user wants to geocode a given table
- prompt: Geocode all customers
- expected_action_call:
{"action_function": "GeocodeTable","arguments":{"tables_to_geocode": ["customers"]}}`
- DeleteAllOutputs – Called by the agent when user requests deletion of all outputs tables in a data model
- Similar to above examples
- DeleteScenarioResults – Called by the agent with user requests deletion of scenario results in the data model
- Similar to above examples
- CreateBlankModel – Called by the agent when user requests for creation of a new blank data model
- Process
- SQL function calls undergo validation to ensure they are executable. This is done using the EXPLAIN command in SQL without the need to actually execute the query.
- Other Non-SQL functions also under go Pydantic validations to ensure that the parameters being selected are from a valid list of parameters
- If validation fails, the Agent retries up to two times before requesting user clarification.
- Some examples of Pydantic validations are given at the end of this section
- SQL RESPONSE FUNCTIONS
- HELPER FUNCTIONS – These serve as an intermediate step before the final response is sent back to the user
- Retry Mechanism
- If an invalid function call is generated:
- The agent is given error feedback.
- A retry prompt is constructed with error details and improvement suggestions.
- The updated history (with retry prompt) is sent to OpenAI again.
- If maximum retries are reached, the Agent informs the user of the failure and requests clarification.
- If an invalid function call is generated:
Pydantic Validation
Some examples of function signatures for Pydantic validatiors defined for function classes are given below. These include validation of syntax as well as business rules.
- SELECTs – Ensure that “SELECT” keyword is present in generated statement, only a single
SELETstatement is returned and the statement is executable.
@field_validator("statements")
def ensure_select_in_statement(cls, v: list[str])
@field_validator("statements")
def ensure_single_select_statement(cls, v: list[str])
@field_validator("statements")
def ensure_select_statement_executable(cls, v: list[str], info: ValidationInfo)- INSERTs – Ensure that “INSERT” keyword is present in generated statement, ensure that
INSERTs are not made to output tables, and the statement is executable.
@field_validator("statements")
def ensure_insert_in_statement(cls, v: list[str])
@field_validator("statements")
def ensure_insert_statement_executable(cls, v: list[str], info: ValidationInfo)
@field_validator("statements")
def ensure_no_inserts_to_output_tables(cls, v: list[str], info: ValidationInfo)- DELETEs – Ensure that “DELETE” keyword is present in generated statement, ensure that
DELETEs are not made to empty tables, and the statement is executable.
@field_validator("statements")
def ensure_delete_in_statement(cls, v: list[str])
@field_validator("statements")
def ensure_no_deletes_to_empty_tables(cls, v: list[str], info: ValidationInfo)
@field_validator("statements")
def ensure_delete_statement_executable(cls, v: list[str], info: ValidationInfo)- UPDATEs – Ensure that “UPDATE” keyword is present in generated statement, ensure that
UPDATESs are not made to empty/output tables, and the statement is executable.
@field_validator("statements")
def ensure_update_in_statement(cls, v: list[str])
@field_validator("statements")
def ensure_no_updates_to_empty_tables(cls, v: list[str], info: ValidationInfo)
@field_validator("statements")
def ensure_no_updates_to_output_tables(cls, v: list[str], info: ValidationInfo)
@field_validator("statements")
def ensure_update_statement_executable(cls, v: list[str], info: ValidationInfo)- DeleteScenarioResultsBase – Ensure that the “baseline” scenario is not selected for deletion
@model_validator(mode="after")
def prevent_delete_of_baseline(self)- CreateBlankModel – Ensure that the data model being created is unique and has a valid name
@field_validator("blank_model_name")
def ensure_model_name_is_unique(cls, v: str, info: ValidationInfo)
@field_validator("blank_model_name")
def ensure_model_name_does_not_contain_forbidden_chars(cls, v: str)Dataset Creation and Fine-tuning Methodology
Data Collection and Preparation
The system employs a three-stage approach to prepare training data:
- Ground Truth Collection
- Human-curated Examples: Carefully selected real-world supply chain queries and their corresponding solutions, focusing on common operational scenarios like inventory management, transportation routing, facility optimization, etc.
- Synthetic Data Generation: Programmatically created examples following industry-standard patterns, ensuring coverage of edge cases and rare scenarios that might not appear in human-curated data.
- Multi-turn Conversations: Complex interaction patterns that simulate real user behavior, including multiple types of user requests in the same conversation.
- Validation Examples: A separate set of challenging and representative examples specifically designed to validate Agent’s performance across different supply chain domains.
- Simplified version of a ground-truth example is given below-
[
{
"prompt": "Do I have any unassigned scenario items? If so, show me scenario item names.",
"sql_statements": [
{
"table_names": [
"scenarioitemassignments",
"scenarioitems"
],
"sql": "SELECT itemname from scenarioitems where itemname not in (select distinct itemname from scenarioitemassignments)"
}
]
}
]- Quality Control
- SQL Validation: Rigorous checking of syntax but executing the SQL queries
- Data Type Consistency: Strict enforcement of proper type casting and data format standardization across all examples
- Schema Compatibility: Validation of table and column references against target database schemas
- Data Diversification – Data diversification refers to the process of selecting a diverse subset of examples from a given dataset. A subset is considered diverse if it covers all tables, SQL statement/action/utility types, prompt wordings, SQL formulations, and edge cases present in the main dataset. Examples that are overly similar, either in wording or expected response, should be excluded in favor of more varied examples. The method is inspired by the paper Data Diversity Matters for Robust Instruction. This paper introduces a diversity-utility optimization method based on a facility location function and a utility term, ensuring the diversified dataset contains high-quality examples. Since we lack a quality measure for our dataset examples, we rely solely on the facility location function (setting the utility term weight to zero).
- Facility Location Function (Diversity) -The facility location function evaluates how well a subset of selected examples represents the entire dataset by calculating the similarity between each example in the dataset and those in the ground set. The function considers the maximum similarity of a new candidate example to the existing ground set. The goal is to maximize this score, ensuring the selected subset covers a wide range of scenarios.
- Utility Function – The utility score reflects intrinsic data properties, such as complexity or quality (e.g., human-labeled data may have higher utility). A weight parameter balances diversity and utility. In our implementation, the utility weight is set to zero by default.
- Example Selection – The algorithm starts with a seed set of examples that ensures coverage across use cases and table names. It iteratively evaluates remaining examples using the diversity-utility function, selecting the one with the highest score at each step. This process continues until the desired number of examples is reached.
Training Data Structure
Each training example follows a carefully designed conversation flow:
- Core Components
{
"messages": [
{
"role": "system",
"content": "Supply chain assistant prompt"
},
{
"role": "user",
"content": "Business query in natural language"
},
{
"role": "assistant",
"content": "table_info/helper tool call to understand schema"
},
{
"role": "function",
"content": "Table schema and metadata or other tool call content"
},
{
"role": "assistant",
"content": "SQL/action/utility function/ChatCompletion call"
},
{
"role": "assistant",
"content": "formatted response"
}
],
"tools": [available_function_definitions
]
}Fine-tuning Process
The fine-tuned model learns tool call structures, including when to call a tool, the correct parameters for tool execution and how to generate valid SQL queries.
DataModel1/
├── select_examples/
├── update_examples/
├── delete_examples/
├── insert_examples/
└── reply_about_me_examples/
...
DataModel2/
├── select_examples/
├── update_examples/
...The implementation follows a systematic approach:
- Pre-training Validation
- Resource Planning: Detailed token count estimation and cost projection for training budget management.
- Dataset Analysis: Comprehensive checks for distribution balance across different query types and complexity levels.
- Format Verification: Automated validation of all example formats and required fields.
- Fine-tuning Process
- Use Case Structure
- Each use case (SELECT, UPDATE, DELETE, etc.) has its own examples
- Examples are organized by data models
- Each example contains:
- Prompt
- Expected SQL statements
- Table names
- Additional metadata (synthetic/human example)
- Data Set Creation
- Process runs in parallel for each data model
- Within each data model, examples are processed by use-case
- Example Processing:
- Examples are converted from JSON to OpenAI fine-tuning format
- Multi-turn conversations are created by combining random examples. This way the Agent learns to handle different use-cases in the same conversation thread and better understand context switching
- Examples:
- First turn: SELECT query
- Second turn: UPDATE statement
- Or: DELETE followed by INSERT
- Maximum 2 turns per conversation currently
- Examples:
- Fine-tuning
- Gather all examples for the data model
- Submit for training
- Training Configuration
- Uses GPT-4 for fine-tuning
- Temperature is set to 0 as we do not want the LLM to be creative with SQL queries and response reproducibility is valued
- The model is trained for 1 epoch
batch_sizeandlearning_rate_multiplierare set toauto
- Use Case Structure
Below are the loss and accuracy plots provided by OpenAI API.
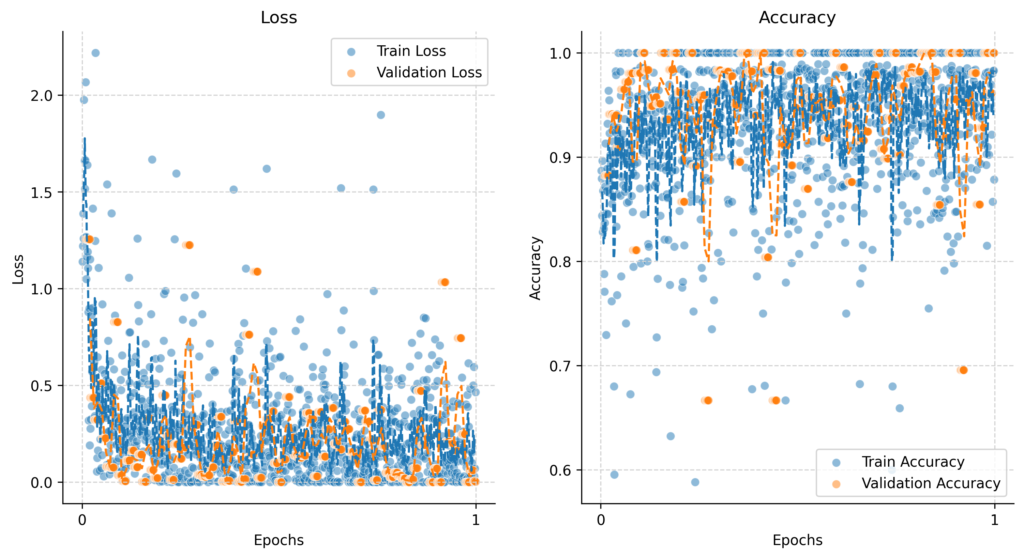
Validation and Error Handling
The validation system operates on multiple levels, ensuring reliable and secure operation. For SQL operations, it checks syntax, verifies table and column existence, tests query executability via EXPLAIN, and compares results for equivalence. Utility calls and Action calls undergo argument type checking and parameter validation, while text responses are evaluated using semantic similarity metrics.
Core Structure
The pipeline consists of three main stages:
- Generate Responses
- Validate Responses
- Aggregate Results
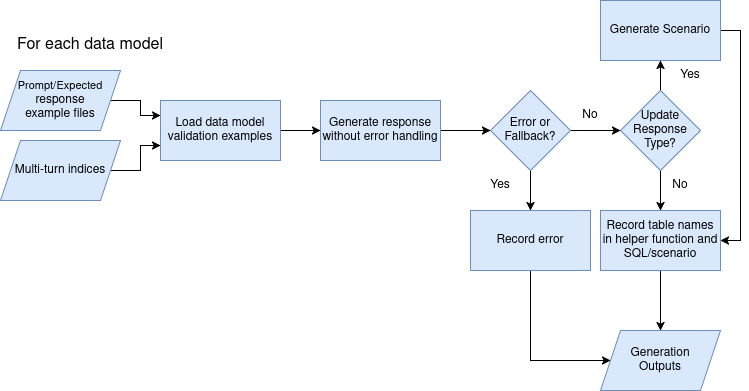
Generate Responses
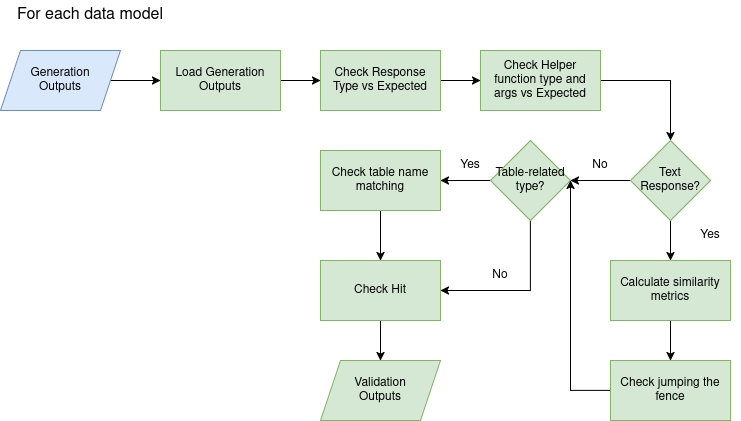
Validate Responses
Error Types During Generation
gen_internal_server_error: OpenAI API issuesgen_internal_bot_error: SQL/Scenario errorsgen_scenario_update_with_nested_select_statements: Nested SELECT parsing failuresgen_scenario_llm_sql_parsing_error: LLM parsing failuresgen_scenario_deterministic_sql_parsing_error: Deterministic parsing failuresgen_fallback_response: Agent returns fallback response
Error Types During Validation
val_scenario_run_fail: Generated scenario not executableval_table_diff: Mismatched table namesval_mismatched_response_type: Wrong response typeval_output_diff: Correct type but different outputval_mismatched_helper_function_type: Wrong helper functionval_mismatched_helper_function_args: Wrong function argumentsval_chat_completion: Unexpected clarification requestval_jumping_the_fence: Non-executable SQL in ChatCompletion
Below is a plot of the share of different error types across all use-case
Hit Criteria
- ChatCompletion Responses
- Verify response type is ChatCompletion
- Check helper function arguments match
- Check for semantic similarly between generated and ground truth response
- compute HIT rate @70% semantic similarity
- SQL Statements
- SELECT: Compare query results (ignoring row/column order)
- INSERT/DELETE: Compare resulting tables
- UPDATE: Compare both tables and derived scenarios
Conclusion
The Leapfrog AI architecture demonstrates a robust approach to building enterprise-grade LLM applications, currently serving hundreds of users across different organizations. Through our extensive experimentation and development process, we’ve uncovered several crucial insights:
Key Learnings
- Fine-tuning Impact
- Fine-tuning the LLM for core skills (SQL generation, scenario management) significantly improved performance
- However, aggressive fine-tuning on technical tasks led to an unexpected regression in general conversational abilities
- We had to specifically fine-tune for maintaining conversational capabilities, effectively teaching the model to balance technical precision with user interaction
- Validation Framework – A comprehensive validation system proved crucial for reliable deployment
Future Directions
As we continue to evolve the system, we’re focusing on:
- Better balancing of specialized vs. general capabilities
- Expanding the validation framework
- Improving multi-turn conversation handling
- Investing in production monitoring systems
The success of the Leapfrog AI demonstrates that with careful architecture, comprehensive validation, and thoughtful fine-tuning, LLMs can be effectively deployed in enterprise environments while maintaining both technical precision and user-friendly interaction. Get started with Leapfrog AI here!
Learn more



