- 12 min read
- Cross-industry
- Jul 2025
Building a deep research multi-agent system

Introduction: From documents to deep research
Ever wished your research could come with a “what did I miss?” button? This post introduces a deep research system we built to enrich long-form documents such as investment reports, legal briefs, or strategic memos by identifying missing context and supplementing them with relevant information from external and internal sources. These documents could leave important questions unanswered or lack up-to-date insights that could support better decision-making. Instead of summarising the content or editing the original report, the system performs structured, autonomous research around the document to uncover what may have been overlooked.
Agentic research systems
In an age where vast volumes of information are readily accessible but often overwhelming, the ability to conduct deep research, that is, to move beyond surface-level summaries and uncover meaningful, non-obvious insights, has become increasingly valuable. Whether analysing investment opportunities, synthesising legal arguments, or reviewing scientific literature, effective research today requires more than just data extraction; it demands context-aware reasoning, critical questioning, and iterative exploration.
Unlike structured tasks with well-defined paths, research is inherently open-ended and unpredictable. Human researchers don’t follow fixed scripts; they continuously adapt their approach based on what they discover, chase leads, revise hypotheses, and ask new questions along the way. This path-dependency and dynamism make traditional, linear AI pipelines poorly suited for deep investigative work.
This is where agentic research systems come in.
Inspired by human reasoning and powered by large language models, our agentic system treats research as an active, self-directed process. Rather than passively consuming documents, it autonomously generates questions on its own, decides which tools to invoke, and iterates across multiple steps. The system can reason and take action in a loop, adjusting its strategy in response to intermediate findings, just like a human analyst would.
The autonomy of the deep research system
This deep research system is built around a modular, agent-driven architecture designed to enable autonomous, tool-augmented investigation. The process begins with parsing a document or set of base documents, such as investment reports or technical briefs, into clean, structured text using any standard document processing libraries like PyPDF, unstructured, or python-docx, etc, depending on the file type. This structured input forms the foundation for downstream research, allowing for reasoning around research question generation, and lets the agent analyse the content and begin exploring beyond what’s written.
A reasoning-enabled language model is used to generate a set of targeted research questions based on the input documents. Unlike standard summarisation or keyword extraction methods, the reasoning model is prompted to actively analyse the content, identify gaps, and formulate questions that uncover missing context, implicit assumptions, or areas where further investigation could yield deeper insight. This ensures that the system doesn’t just restate what’s already present in the text, but instead highlights what needs to be explored further.
Each question triggers an independent and asynchronous execution of the research agent built using the ReAct (Reasoning + Acting) methodology. This agent can independently decide how to investigate the question: selecting tools (such as web search, internal knowledge search, or follow-up question generation), executing calls, evaluating intermediate outputs, and adapting its strategy over multiple steps. The agent’s behaviour mimics an iterative reasoning loop: Reason (think, decide), and Act, where each step builds on the previous one.

This design enables the system to handle open-ended or ambiguous tasks that would be difficult to address with static, single-pass pipelines. Instead of hardcoding a fixed process, agents dynamically determine how to proceed based on intermediate findings, making the system more robust and capable of exploring complex topics.
The system generates two types of summaries asynchronously:
- A document summary, which concisely captures the original content of the input document without incorporating any AI-generated information or external findings. This separation ensures a clean, unbiased representation of the source material.
- An AI-generated insight summary, which synthesises the findings from the agent-driven Q&A process while using the original document as context.
These two summaries are then merged to form a single, consolidated deep research report. The final output reflects both the original content and the additional insights uncovered through autonomous investigation, offering a more complete and actionable view of the topic.
Tooling the research agent
In this system, tools represent discrete capabilities that the agent can invoke as part of its reasoning and action process. Each tool is registered with a specific description that defines its intended use. These descriptions are critical, as they help the agent determine when to use a tool based on the nature of the research question and the type of information provided.
The first version of the Deep Research agent was given these tools to work with:
1. Search Tools (Web + Internal Knowledge Base)
Search is performed using two tools asynchronously—one for public information and one for internal knowledge, giving the agent access to a broad range of sources.
- Web Search
Searches the public web to find general information, news, and external resources about any topic. This tool is useful when the agent needs current events, background context, or information not available in internal systems. In the current implementation, this tool interfaces with either OpenAI’s web search or Google Gemini’s web search API.
Example Tool description:
“Search the public web to find general information, news, and external resources about any topic.” - Internal Search (RAG-as-a-Service)
This tool routes queries to a hosted RAG system via a chat-style endpoint. It queries the internal company knowledge base and documentation to find relevant information. This tool is used to retrieve proprietary insights, historical records, or domain-specific context.
Example Tool description:
“Search through internal company knowledge base and documentation to find relevant information.”
Together, these tools form the core of the system’s search capability. The agent is configured to invoke both internal and external search tools asynchronously whenever additional information is needed, ensuring faster and comprehensive coverage from both proprietary and public sources.
2. Follow-Up question generator
This tool is used when the agent determines that a research question is too broad, ambiguous, or underspecified. It generates refined follow-up questions to clarify intent or narrow the scope before proceeding with retrieval or reasoning.
Example Tool description:
“Use this tool when the research question is unclear, too broad, or needs clarification before searching or answering.”
Reason meets action: The ReAct framework
The ReAct framework (Reason + Act) is a prompting strategy for large language models that combines verbal reasoning with tool-based actions in an interleaved manner. Traditional prompting methods typically separate reasoning (e.g., Chain-of-Thought) from tool use or focus on direct action execution without explicit internal reasoning. ReAct bridges this gap by enabling the model to alternate between thinking steps (“Think”) and execution steps (“Act”), allowing for more dynamic and context-sensitive task solving.
At each step, the agent can:
- Generate a thought that reflects its current reasoning, helping structure the plan, interpret previous observations, or decide what to do next.
- Choose an action such as calling a search tool, asking a follow-up question, or finishing the task.
This pattern of alternating “Think → Act → Observation” steps allows the agent to maintain a transparent chain of reasoning, retrieve and incorporate new information through tool use, and adjust its decisions as the investigation progresses.
ReAct is particularly effective for tasks that require iterative information gathering and knowledge-grounded reasoning, such as multi-hop question answering, fact verification, and interactive decision-making. In these settings, reasoning improves the quality of tool use, and tool use enriches the agent’s reasoning, creating a feedback loop that’s more robust and interpretable than either reasoning or acting alone.
In our system, ReAct agents use this approach to investigate open-ended research questions: deciding when to search externally, when to clarify ambiguities, and how to synthesise retrieved information into a coherent answer, all while keeping their reasoning trace visible and auditable.
Multi-agent research loop (ReAct + tools)
At the core of the deep research system is a research execution loop powered by a single ReAct-enabled agent. While only one agent instance is initialised, with all tools registered once, it is invoked asynchronously for each research question, allowing independent research tasks to be executed. This architecture results in a multi-agent execution pattern, where each invocation maintains its own context, reasoning state, and tool usage history. Notably, the system is built from the ground up in Python, without using agentic orchestration frameworks. This design choice ensures transparency and full control over how reasoning, tool use, and asynchronous task execution are handled.
Each research question acts as a starting point, not a query to be answered definitively, but a prompt to initiate exploration. The agent’s role is not to return a final answer, but to gather and synthesise as much useful information as possible within a fixed number of iterations. In each step, the agent updates its working query based on newly retrieved information or internal reasoning, allowing the line of investigation to evolve dynamically. This makes each iteration an opportunity to refine understanding, discover new angles, and expand the scope of the information retrieved.
ReAct Breakdown: Think → Decide → Act → Think………
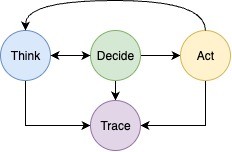
The agent follows the ReAct loop, alternating between reasoning and tool use to drive a multi-turn information-gathering process.
1. Think
The agent reflects on the current state of the investigation and produces a natural language reasoning step. This includes interpreting the research question, reviewing previously retrieved results, identifying gaps, and synthesising partial findings. Based on this reasoning, the agent outputs a response that indicates what to do next, either proposing a final summary or suggesting a tool to invoke.
This response is appended to the agent’s context as part of its trace, ensuring transparency and continuity across steps.
Example:
“Previous results covered regulatory risks, but I haven’t yet found financial risks. I should look for quarterly reports or earnings mentions.”
→ (Output: Use search tool)
2. Decide
The system then interprets the agent’s reasoning output to determine the next step. If the agent has proposed using a tool, the execution proceeds to the Act step with the selected tool and updated query. If instead the response indicates a final answer, the agent returns this output and ends the loop for that question.
3. Act
The agent executes the selected action. This could be a query to the internal knowledge base, a web search, or a step to generate follow-up questions. The output is added to the agent’s context and used to inform subsequent reasoning steps.
4. Trace
After every step, whether it’s reasoning, tool selection, or execution, the agent traces its thought process and results by appending them to the context. This continuous tracing ensures that each decision, action, and observation is preserved, allowing the agent to maintain a coherent and transparent reasoning history throughout the loop.
The loop continues: Think → Decide → Act, with each step traced into the agent’s context, until the iteration limit is reached. At that point, the agent generates a final output aggregating the information gathered across all steps, providing a structured and transparent record of the research process.
Managing citations across models and tools
A key aspect of building trust in AI-assisted research is ensuring that every insight or claim can be traced back to its source. In this system, citation handling is tightly integrated into the research loop, allowing references to be tracked consistently across multiple models and tools.
Each tool or language model, whether it’s OpenAI, Gemini, or an internal retrieval system, may return citations in different formats. To manage this variability, the system includes logic to extract and normalise references into a unified inline format. This allows all citations, regardless of source, to be handled in a consistent and structured way throughout the workflow.
As each tool returns new information, citations are registered into a centralised registry. This registry assigns unique identifiers to each reference and ensures consistency across asynchronous research tasks. Even when multiple queries are processed asynchronously, the citation registration process avoids duplication and preserves a reliable mapping.
When results are aggregated into a final report, the system remaps citation identifiers as needed to ensure that references remain consistent and correctly aligned with the inline citations. The output is then scanned for all cited sources to generate a clear and complete reference list.
The final report can present citations in various formats—numbered brackets, footnotes, or endnotes—depending on the intended output. Internally, we maintain all citations inline using a custom XML-like tag format: <cite=id/>. This makes it easy to parse, transform, and render citations consistently across downstream systems. And because the citation pipeline is model-agnostic and extensible, supporting a new source only requires defining how to extract its references; the rest of the system handles normalisation, registration, and integration automatically.
Conclusion
This deep research architecture showcases a new paradigm in how we can approach complex, open-ended information tasks: not with rigid pipelines or one-shot prompts, but with autonomous agents capable of reasoning, using tools, and adapting their strategies over time. By combining the ReAct framework with structured tool use and asynchronous execution, the system emulates the behaviour of a diligent analyst, breaking down problems, asking follow-up questions, and continuously refining its understanding.
What makes this approach powerful is not just its ability to extract information, but its capacity to explore, interpret, and build insight—layer by layer, step by step. It transforms research from a static process into a dynamic, iterative dialogue between agent, tools, and data.
As AI agents continue to improve, the boundary between “automation” and “analysis” will blur. What we’re seeing here is not just a better summarizer or searcher, but a foundation for systems that can reason their way through ambiguity, discover what’s missing, and generate new lines of inquiry on their own.
The implications extend well beyond the example in this post. From policy and legal analysis to scientific exploration and market intelligence, the potential for autonomous research agents is vast.
References
Learn more



